

AI Is Everywhere... But What’s Left for Us Developers?
If you’ve been anywhere near tech lately, you know the drill:
AI is everywhere - splashed across marketing slides, dominating landing pages, slapped onto every "new release" announcement.
Agentic coding. Agent mode. GitHub Copilot.
Agents here, agents there, agents everywhere.
But here’s the real question: When the shiny marketing slides fade, what’s actually left for us developers?
That’s exactly what we’ll explore in this new blog series.
This post is your overview - the lay of the land.
In upcoming posts, we’ll zoom in on each concept, share code samples, and dig into real-world use cases.
An Engineer’s Perspective on AI
When thinking about AI as a big, world-changing topic, there are plenty of angles to take - ethics, business models, the whole "will AI replace jobs" discussion.
But here, I’m taking the engineering perspective.
So my starting point is:
What does the widespread availability of LLMs mean for me, a lead software engineer working with product development teams?
Short answer: a lot.
Probably more than you expect right now.
Let’s break it down.
1. Bridging the Gap Between Messy Human Data and Clean Digital Processes
Human-centered processes produce messy data. Think analog, scattered, unstructured - the polar opposite of the neat rows and columns our systems love.
Example time:
Let’s imagine you work for an insurance company.
In the claims process, customers submit all sorts of input: damage reports, cost estimates, photos, phone calls, even hand-written letters (yes, still a thing).
You can’t control how people submit this data - good luck enforcing a clean, machine-readable format.
Here’s where AI steps in:
- LLMs + OCR can read scanned documents and even transcribe handwriting.
- Speech-to-text models can turn phone calls into searchable transcripts.
- Vision LLMs can tag and classify photos - and even analyze videos.
- For instance, Qwen 2.5 VL can handle both images and videos.
Once we’ve converted anything into text, we’ve moved into LLM territory - and that’s where the magic happens.
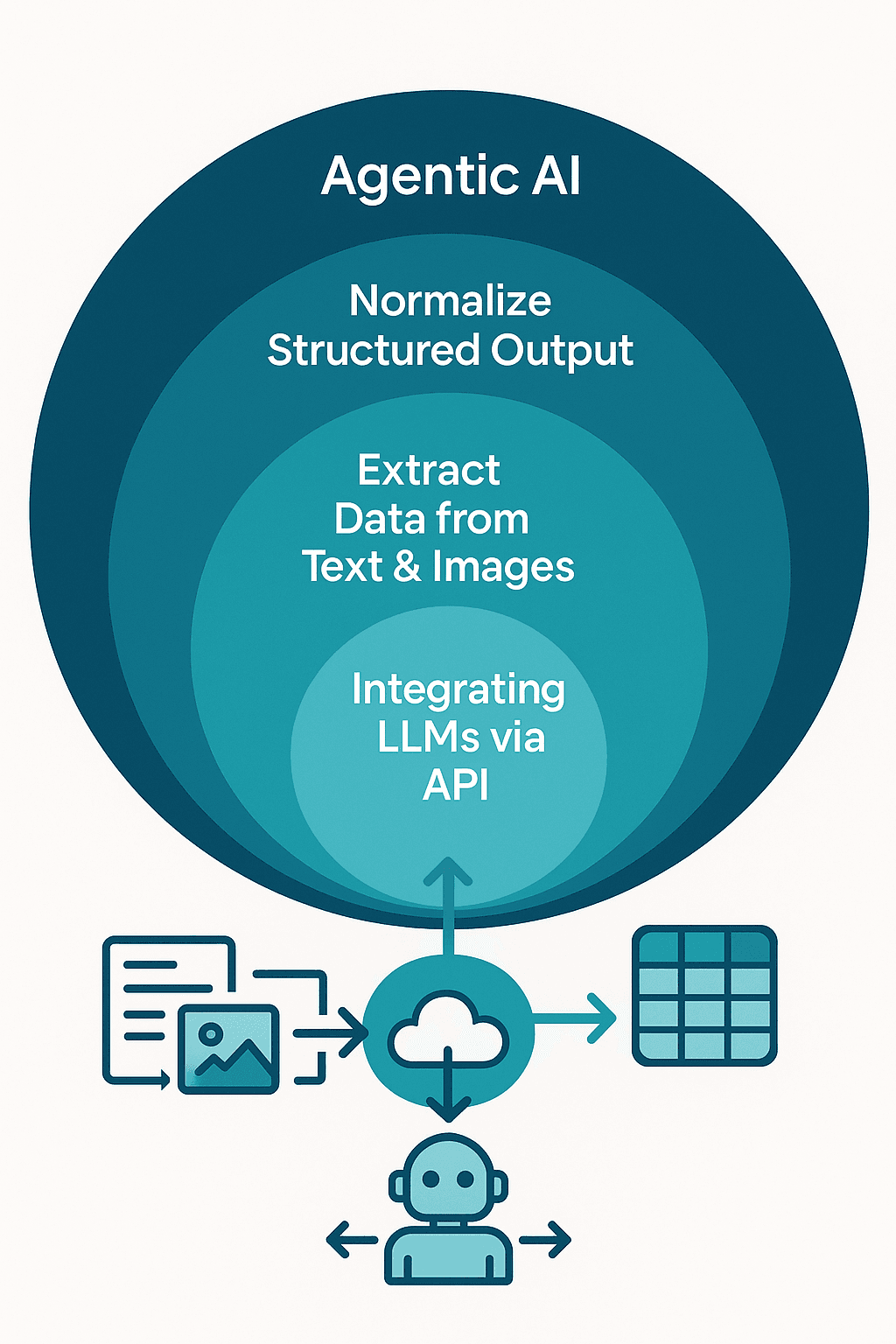
2. Turning Text into Structured Data
After we’ve bridged the messy-to-text gap, the next step is often semantic structuring.
For example:
Feed the LLM an entire damage report and tell it to output a structured JSON with:
- Review date
- Reviewing person
- Email address
- Numeric cost estimate
- Text description of damage
Boom - you’ve gone from a totally unstructured blob to a clean dataset you can process deterministically:
- Check if the report date violates business rules
- Email the reviewer for more info
- Trigger a payment if everything looks good
This is where LLMs stop feeling like "magic black boxes" and start becoming practical data pipelines.
3. Adding Agentic AI to the Cake
So far, AI has been a tool in our toolbox - performing well-defined, narrow tasks inside deterministic workflows.
But we can flip that model: AI as the orchestrator.
In our insurance example, imagine giving an AI agent:
- Access to customer & incident databases
- A clear set of instructions for processing new documents
- Rules for approving or escalating payments
Now the agent decides which tools to call, in what order.
Would I trust it to autonomously approve big payouts? No way.
But as a rapid prototyping tool? Game changer.
This shines when:
- The path to a solution isn’t obvious from the start
- The problem is unique to each customer
- There are too many possible variations for a deterministic implementation
Think Azure Copilot diagnosing issues in complex, custom cloud environments. The agent can:
- Iteratively gather logs and config data
- Try fixes
- Observe the results
- Continue until the problem is solved (or escalated)
4. Do More with Less: Fine-Tuning
For early experiments, you can lean on the big frontier models like GPT-5, Claude 3.5, Gemini Ultra, etc.
But for production, smaller fine-tuned models can be faster and cheaper.
Example:
If you just need to help your marketing team write product descriptions in your brand voice, throwing GPT-5 at it will work - but it’s overkill.
Fine-tuning something like Qwen3-7B with LoRA/QLoRA on a small dataset can get you similar quality, higher throughput, and much lower cost.
Rule of thumb:
- ✅ Worth it when you do thousands of inferences daily
- ❌ Overkill for a few dozen runs a month
5. Vectorizing Knowledge
LLMs are trained with "world knowledge" baked into their weights.
But what if you want them to also know your private documentation or customer history?
Enter vector databases.
- Convert your data into embeddings
- Store them in a vector DB
- Search by semantic similarity
- Inject the most relevant results into the LLM prompt
This is RAG (Retrieval-Augmented Generation) - a way to extend an LLM’s knowledge without retraining it.
Wrapping Up
This post was the high level view* of AI in engineering - bridging messy data, structuring it, empowering agents, fine-tuning, and extending knowledge with vectors.
In the next posts, we’ll zoom into each concept with deep dives, architecture diagrams, and real code.
Because AI hype is fun... but AI engineering is where the real work (and fun of course) happens.